Time Ordering Shuffling for Improving Background Subtraction
B. Laugraud, P. Latour, and M. Van Droogenbroeck
Abstract
By construction, a video is a series of ordered frames, whose order is defined at the time of the acquisition process. Background subtraction methods then take this input video and produce a series of segmentation maps expressed in terms of foreground objects and scene background. To our knowledge, this natural ordering of frames has never been questioned or challenged.
In this paper, we propose to challenge, in a prospective view, the natural ordering of video frames in the context of background subtraction, and examine alternative time orderings. The idea consists in changing the order before background subtraction is applied, by means of shuffling strategies, and re-ordering the segmentation maps afterwards. For this purpose, we propose several shuffling strategies and show that, for some background subtraction methods, results are preserved or even improved. The practical advantage of time shuffling is that it can been applied to any existing background subtraction seamlessly.
Keywords: Background subtraction, motion analysis, change detection, time ordering shuffling, updating strategy
1 Introduction
Background subtraction is an essential task in many video applications (such as video-surveillance), that consists in discriminating between moving objects and the background of the scene. While this operation seems obvious, it is very difficult to accommodate to the large variety of scenes and to deal with dynamical effects such as sudden lighting changes, dynamic backgrounds, shadows, etc. Therefore, many techniques have been proposed and reviewed for background subtraction (see for example Brutzer
et. al. [11], Bouwmans
[12, 13], or Jodoin
et. al. [6]).
Background subtraction involves a background model and several steps: initialization, segmentation, and updating. During the initialization, the algorithm builds a background model. We are not focusing on initialization in this paper. Therefore, we assume that the learning sequence is long enough to build a model of the background. After initialization, we perform a segmentation, that produces the binary foreground/background segmentation map, and update the background model. The quality of the final segmentation maps is usually expressed in terms of False (F) or True (T) Negatives (N) or Positives (P), or with global measures such as the
F1 score
[1], defined as:
It is assumed that only an appropriate background model, which is dynamic by essence, can lead to a good performance. This implies an efficient adaptation of the model over time, which is the purpose of the updating step.
Updating the background model is challenging because, among others, there is a trade-off between the adaptability to fast changes and the required inertia to avoid the rapid inclusion of abandoned objects into the background. Consequently, the updating mechanism, which is intrinsically related to the segmentation step, is an essential part of any background subtraction process.
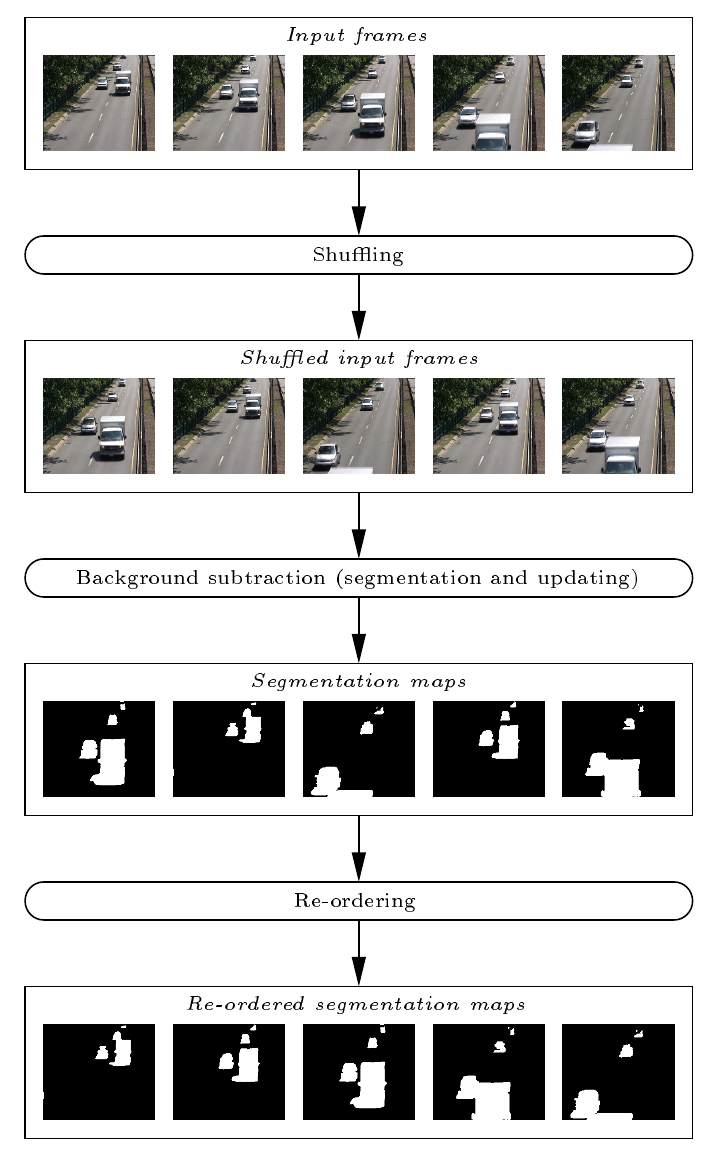
The goal of this paper is to question the impact of changing the time ordering of frames for the segmentation and updating phases; the flowchart of our method is given in Figure
1↓.
This paper is organized as follows. Section
2↓ describes several strategies for changing the natural time ordering. These strategies are evaluated on a selection of sequences that are part of the Change Detection 2014 dataset
[15] (denoted CDnet 2014 hereafter), and results are reported in Section
3↓. Finally, Section
4↓ concludes this paper.
2 Time shuffling strategies
The natural order (which is the chronological one) is the most common order, although it might happen that some events are easier to interpret by running a video sequence backwards. In the field of background subtraction, some authors have recently tried to build background models that are less sensitive to the chronological order. For instance, while Wang and Suter have proposed a non parametric model that is updated by forgetting the oldest samples first
[5], Barnich and Van Droogenbroeck rely on a random selection of samples to be replaced
[10]; in this case, a video sequence is not seen as an
ordered list of frames anymore, but rather as a
collection of frames
[8].
In the following, we first introduce the shuffling principle and then elaborate on a random policy and on deterministic shuffling strategies.
2.1 Principle
The time shuffling principle is the following. Let
I be the ordered set of time indices of an
N-frames long video sequence;
I is then equal to
{1, 2, …, N}, and the video
V comprises the ordered frame sequence
F1F2…FN. The purpose of time shuffling consists to apply a
shuffling strategy first, in order to obtain a new video whose frames are re-ordered. For example, after time shuffling, we have
F13F2FN…F1. This new video sequence is used as an input for a background subtraction algorithm. This results in a video sequence made of the corresponding segmentation maps
S13S2SN…S1. Finally, we recover the original order for the frames to obtain the output sequence
S1S2…SN. The whole process is illustrated in Figure
1↑.
2.2 Random time shuffling strategy
In practice, we take for granted that the natural, chronological, time order is the most appropriate for dealing with videos. However, this has never been extensively checked. The opposite conception to the chronological time ordering is the absence of any order, that is, an entirely random ordering.
There are two reasons which justify the fact that we are interested in testing a random frame order. The first reason is that, since it can be seen as the opposite strategy to the forwards (chronological) ordering, we hope to span a large set of possible strategies and derive some insights on the importance of any kind of ordering. The second reason is that it is very difficult to imagine, at this stage of knowledge, a particular deterministic ordering. More precisely, if we introduce two of them in the next section, we remain unsure about the relevance of other non chronological deterministic strategies.
2.3 Deterministic time shuffling strategies
A more conservative approach consists in avoiding a random ordering. New strategies, that are deterministic, can be based on the content, on the time difference, or on both. In this paper, we examine two strategies based on the difference
δ between any pair of frames. Let
F1 and
F2 be two frames, we compute the difference as follows:
where
p is a pixel location taken in the frame of size
h × w.
Once we have computed all the differences, we choose an order that minimizes or maximizes the differences between successive images. The first strategy, named δmin, is designed to minimize the amount of energy accumulated by δ. The underlying justification for proposing this strategy is that some algorithms are designed to accommodate to small variations in the image content and that most algorithms have troubles for dealing with large changes.
The reason for the strategy that maximizes the differences (strategy named δmax hereafter) is different. We want to evaluate if background subtraction techniques are performing better if they learn large changes as soon as possible, instead of learning them progressively. This would result in a model capable to embrace large changes earlier during the sequence, and a smooth adaptation to small changes later in the sequence.
Note that all the strategies are equally applicable to any type of background subtraction technique, because we do not change the techniques themselves. Despite that, the choice of a strategy directly impacts on the performance of the updating scheme, as the methods are not all equally designed to deal with small or large changes.
2.4 Implementation of the deterministic strategies
Ideally, to implement our proposed deterministic strategies, we should look for the global optimum by finding the index order that minimizes or maximizes the cumulative difference energy. However, this exhaustive search is intractable. Thus, despite that, from a theoretical perspective, it is sub-optimal to proceed step by step (in other words, to find the new frame index at each step), an iterative algorithm has been implemented using this method to carry out the experiments of this paper.
Let Ωi and Φi be two ordered sets of indices built after the ith iteration (starting from 1), whose elements correspond to the remaining frames to shuffle and to the frames that have been shuffled, respectively. Considering the two initial sets Ω0 = I and Φ0 = ∅, the operations performed during the ith iteration of the developed iterative algorithm are the following:
-
Select the element ki ∈ Ωi − 1 which minimizes or maximizes the cumulative difference energy according to the chosen strategy. Note that the selection of k1 is discussed in Section 3.1↓.
-
Construct the set Ωi = Ωi − 1∖{ki}.
-
Construct the set Φi = Φi − 1∪{ki}.
It should be noted that, applied on a N-frames long video sequence, the algorithm terminates after N iterations. In such a case, considering that P(I) is a permutation of I, we have that ΩN = ∅, and ΦN = P(I) which is the set of indices for the shuffled images.
In the example of Section
2.1↑, at the first iteration, once the frame indexed by
13 is selected, the sets
Ω1 = {1, …, 12, 14, …, N} and
Φ1 = {13} are built in such a way that this frame is removed from the set of the next candidates to select, and then included into the set of the shuffled frames.
3 Experiments and results
This section discusses preliminary results obtained for different shuffling strategies. First, we present how we deal with the initialization, then we discuss the chosen dataset, and finally we present our results.
3.1 Initialization
It is common acceptance that a background subtraction technique must initialize its model and that the first frames of a video sequence are used to build the model. Here, we have the choice to preserve the initial order for the initialization frames or to shuffle them. We decided to preserve the order during the initialization step. By doing so, our experiments highlight the behavior of background subtraction techniques during the dynamic updating process only, without requiring any specific assumption about the initialization mechanism. As a consequence, we arbitrarily decided that the algorithm presented in Section
2.4↑ selects the first shuffled frame (
k1) according to the differences
δ between the last initialization frame and the frames indexed by the elements of
Ω0.
3.2 Dataset
In our experiments, we have used the CDnet 2014 dataset
[15]. It is composed of 53 video sequences whose resolution varies from
320 × 240 to
720 × 576 pixels and duration from
600 to
7999 frames. The video sequences are provided with a ground truth annotated at the pixel level and they are divided among 11 categories to focus on specific challenges: Bad Weather, Baseline, Camera Jitter, Dynamic Background, Intermittent Object Motion, Low Framerate, Night Videos, PTZ, Shadow, Thermal, and Turbulence.
This dataset has several major advantages. First, as it is accompanied by ground truth segmentation maps, it is possible to perform an accurate evaluation
[9] of our results. Second, since it contains many video sequences that cover a large variety of application scenarios, it offers the possibility to determine in which context the time ordering shuffling is relevant. And, last but not least, as it contains long sequences, it is more meaningful for the evaluation of time shuffling strategies than a dataset with very short sequences.
It should be noted that all the sequences of the CDnet 2014 dataset have been used, except for the ones from the PTZ category (where one model might fall short for dealing with the scenes), and the Low Framerate category (where motion between consecutive frames might be too large to understand the behavior of our shuffling strategies).
3.3 Background subtraction algorithms
In this paper, we consider six background subtraction algorithms, all of them operating at the pixel level, to challenge the relevance of time shuffling strategies. The simplest one, the exponential filter (denoted “Exp. Filter”), applies a temporal exponential filter on the observed value and thresholds the result. We have also used two mixture of Gaussians techniques, dedicated to the segmentation of scenes with dynamic backgrounds: the technique by Stauffer and Grimson
[4] (“MoG G.”), and the one by Zivkovic, which adapts the number of Gaussians over time
[16] (“MoG Z.”). We also consider the VuMeter algorithm, proposed by Goyat
et. al. [14], which is a non parametric method that estimates the background with a probability mass function. In this technique, the estimation is derived from the temporal histogram of the observed values.
The ViBe algorithm
[10], proposed by Barnich and Van Droogenbroeck, is an alternative non parametric method which compares an observed value to a set of past samples using an Euclidean distance. Note that in order to update its model, ViBe combines a spatial propagation mechanism with a random sampling policy. To our knowledge, ViBe is the first technique to consider a non chronological policy for updating the model. Therefore, it is also a good candidate for testing shuffling strategies.
The last method we have considered is an approach based on self organization through artificial neural networks, the so-called SOBS algorithm, as proposed by Maddalena and Petrosino
[7], whose idea is inspired from biologically problem-solving methods. It should be noted that the implementations of these algorithms are provided by the BGSLibrary
[2] or by the authors.
3.4 Results and interpretation
Obviously, shuffling frames if a scene cut or illumination change occurs is irrelevant because background models before and after such an event are different. Therefore, we only use video sequences that do not contain this type of events; sequences of the CDnet 2014 dataset comply with this assumption.
Likewise, one may wonder on the practical feasibility of a shuffling mechanism that would shuffle frames from the whole sequence. While we agree that, in practice, one should work with slices of the video sequence (by 100 frames for example), we perform experiments on the whole sequence because it helps to understand the impact of re-ordering frames prior to segmentation; by doing this on parts of the video sequence, we might not be able to evaluate the impact correctly. In addition, it should be noted that this problem of causality is nonexistent for off-line video processing.
|
|
Technique and strategy
|
|
|
Exp. Filter
|
MoG G.
|
MoG Z.
|
VuMeter
|
ViBe
|
SOBS
|
|
Category
|
fw
|
rd
|
fw
|
rd
|
fw
|
rd
|
fw
|
rd
|
fw
|
rd
|
fw
|
rd
|
|
Bad Weather
|
0.35
|
0.28
|
0.69
|
0.68
|
0.74
|
0.74
|
0.49
|
0.74
|
0.62
|
0.66
|
0.63
|
0.62
|
|
Baseline
|
0.37
|
0.34
|
0.66
|
0.65
|
0.79
|
0.77
|
0.52
|
0.57
|
0.78
|
0.80
|
0.77
|
0.71
|
|
Camera Jitter
|
0.23
|
0.22
|
0.45
|
0.47
|
0.51
|
0.51
|
0.49
|
0.52
|
0.54
|
0.54
|
0.44
|
0.44
|
|
Dyn. Background
|
0.09
|
0.09
|
0.26
|
0.27
|
0.42
|
0.41
|
0.44
|
0.57
|
0.47
|
0.47
|
0.17
|
0.17
|
|
Intermittent Obj.
|
0.29
|
0.31
|
0.43
|
0.49
|
0.46
|
0.49
|
0.20
|
0.31
|
0.41
|
0.46
|
0.51
|
0.51
|
|
Night Videos
|
0.26
|
0.20
|
0.38
|
0.36
|
0.37
|
0.36
|
0.30
|
0.28
|
0.39
|
0.38
|
0.35
|
0.35
|
|
Shadow
|
0.40
|
0.28
|
0.69
|
0.63
|
0.71
|
0.69
|
0.46
|
0.56
|
0.73
|
0.71
|
0.65
|
0.60
|
|
Thermal
|
0.48
|
0.61
|
0.52
|
0.67
|
0.63
|
0.63
|
0.29
|
0.49
|
0.52
|
0.60
|
0.76
|
0.74
|
|
Turbulence
|
0.07
|
0.07
|
0.30
|
0.25
|
0.53
|
0.52
|
0.54
|
0.53
|
0.67
|
0.57
|
0.17
|
0.17
|
|
Dataset
|
0.28
|
0.27
|
0.49
|
0.50
|
0.57
|
0.57
|
0.41
|
0.51
|
0.57
|
0.58
|
0.50
|
0.48
|
Table 1 F1 scores for the forwards (fw) ordering and the random shuffling of frames (rd). While we believe that averaging F1 scores is questionable, we still provide the mean values for the whole dataset in the last row, for convenience.
In Table
1↑, we present the
F1 scores for the set of background subtraction algorithms described in the Section
3.3↑. It is difficult to draw definitive conclusions from these experiments. In most cases, there are no big differences, despite that the random shuffling strategy is completely opposite to the chronological ordering. Only for the SOBS algorithm did we notice a significant performance decrease. We believe that this might be due to the small number of templates used in this technique and its inability to deal with a wide variety of background templates, such as that encountered when shuffling the video frames. Likewise, the exponential filter has a very limited memory capability. Therefore, it is counter-productive for it to try to estimate the model with shuffled frames.
In a second series of experiments, we compare the three new ordering strategies (random,
δmin, and
δmax) and the chronological ordering (forwards) for a subset of categories only (it was impossible to check all our ideas, because there are too many possible deterministic strategies). Results for these experiments are given in Table
2↓ for the Baseline category (which gathers the most “standard” type of sequences), in Table
3↓ for the Camera Jitter category (which gathers sequences captured with unstable cameras), in Table
4↓ for the Dynamic Background category (which gathers outdoor sequences with moving backgrounds), and in Table
5↓ for the Intermittent Object Motion category (which gathers sequences with foreground objects that remains stationary for some time). With all the cautiousness required by our prospective experiments, we can formulate the following observations:
-
The δmax strategy is usually not the best one. This means that algorithms for background subtraction are intrinsically mainly designed to handle small changes instead of large ones. This is not really surprising, but these experiments seem to confirm that intuition.
-
We observed that the δmin strategy tends to mimic the forwards ordering, except when large changes occur in the image. Since computing δmin is time consuming, it appears that the forwards ordering is more adequate. However, one should observe that δmin always improves the segmentation of the sequences belonging to the Camera Jitter category (Table 3↓). This is coherent with the fact that background subtraction techniques are better in adapting to small changes.
-
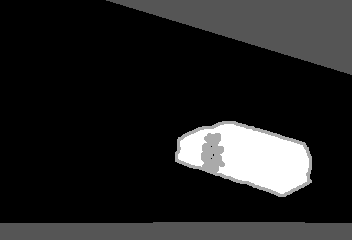
The forwards strategy is never a clear winner for the video sequences of the Camera Jitter category (Table 3↓) and at least one of shuffling strategies improves the performance with respect to that of the natural ordering. This could be explained by the fact that shuffling the frames might reduce the amount of differences, due to camera motion, between consecutive frames (this is, again, coherent with our observation for the δmin strategy). Figure 2↓ illustrates the improvement obtained by the use of a shuffling strategy on a sequence of the Camera Jitter category.
-
Except for the SOBS algorithm, the forwards strategy is never the best for the video sequences of the Intermittent Object Motion category (Table 5↓). Our feeling is that, because random and δmax strategies will interlace frames with and without stationary objects, they slow down the inclusion of those objects into the background (which is considered as being the right approach by the designers of the CDnet dataset).
-
For most methods, the random strategy outperforms the natural ordering in the Thermal category (Table 1↑). Figure 3↓ illustrates the improvement obtained by the use of a shuffling strategy on a sequence of this category.
-
For the VuMeter algorithm, in all cases, at least one shuffling strategy increases the score of the chronological ordering.
-
For the baseline category, there is no clear winning strategy. It is interesting to note that ViBe, which natively incorporates a random updating policy, performs best for the random shuffling strategy. This suggests that the sequences have backgrounds with a lot of inertia, so that the modification of the time order has no large impact on the performances.
-
It is worth considering alternative time orderings as the forwards strategy is not always the best strategy. This raises questions about the dynamic behavior of background subtraction techniques in general.
|
|
Strategy
|
|
Technique
|
forwards
|
random
|
δmin
|
δmax
|
|
Exp. Filter
|
0.374
|
0.342
|
0.374
|
0.349
|
|
MoG G.
|
0.658
|
0.657
|
0.658
|
0.653
|
|
MoG Z.
|
0.794
|
0.778
|
0.791
|
0.782
|
|
VuMeter
|
0.523
|
0.572
|
0.525
|
0.489
|
|
ViBe
|
0.777
|
0.801
|
0.778
|
0.790
|
|
SOBS
|
0.771
|
0.710
|
0.760
|
0.755
|
Table 2 F1 scores for different shuffling strategies applied on the Baseline category.
|
|
Strategy
|
|
Technique
|
forwards
|
random
|
δmin
|
δmax
|
|
Exp. Filter
|
0.228
|
0.222
|
0.265
|
0.237
|
|
MoG G.
|
0.452
|
0.469
|
0.504
|
0.505
|
|
MoG Z.
|
0.505
|
0.505
|
0.515
|
0.498
|
|
VuMeter
|
0.486
|
0.519
|
0.503
|
0.498
|
|
ViBe
|
0.542
|
0.539
|
0.558
|
0.537
|
|
SOBS
|
0.437
|
0.437
|
0.439
|
0.443
|
Table 3 F1 scores for different shuffling strategies applied on the Camera Jitter category.
|
|
Strategy
|
|
Technique
|
forwards
|
random
|
δmin
|
δmax
|
|
Exp. Filter
|
0.094
|
0.091
|
0.094
|
0.090
|
|
MoG G.
|
0.258
|
0.270
|
0.258
|
0.260
|
|
MoG Z.
|
0.420
|
0.410
|
0.420
|
0.410
|
|
VuMeter
|
0.441
|
0.572
|
0.441
|
0.417
|
|
ViBe
|
0.472
|
0.473
|
0.471
|
0.463
|
|
SOBS
|
0.169
|
0.166
|
0.169
|
0.167
|
Table 4 F1 scores for different shuffling strategies applied on the Dynamic Background category.
|
|
Strategy
|
|
Technique
|
forwards
|
random
|
δmin
|
δmax
|
|
Exp. Filter
|
0.287
|
0.306
|
0.284
|
0.302
|
|
MoG G.
|
0.426
|
0.483
|
0.414
|
0.454
|
|
MoG Z.
|
0.461
|
0.490
|
0.462
|
0.461
|
|
VuMeter
|
0.197
|
0.309
|
0.200
|
0.204
|
|
ViBe
|
0.408
|
0.460
|
0.408
|
0.431
|
|
SOBS
|
0.514
|
0.508
|
0.514
|
0.508
|
Table 5 F1 scores for different shuffling strategies applied on the Intermittent Object Motion category.
4 Conclusions
In this prospective paper, we examine how changing the time ordering of video frames impacts on the the task of background subtraction. This questions the notion of chronological order and introduces a new view on the problem. For that purpose, we have developed several shuffling strategies for re-ordering the frames and have evaluated them for different algorithms on the CDnet 2014 dataset. This highlights whether techniques are or not dependent with respect to the frame order, but it also shows that a principle applicable to any background subtraction technique can affect the performance. Our results remain difficult to interpret, because they illustrate that the updating process of some algorithms is sensitive to the time ordering of the frames, while other techniques are less sensitive to it. In addition, we observe that the chronological ordering is rarely the best one for background subtraction, and that for some categories of video sequences, at least one shuffling strategy systematically improves the F1 score. While this is a question to be challenged in future work, it also points out that the general understanding of background subtraction updating mechanisms has to be refined.
References
[1] A. Baumann, M. Boltz, J. Ebling, M. Koenig, H. Loos, M. Merkel, W. Niem, J. Warzelhan, J. Yu. A Review and Comparison of Measures for Automatic Video Surveillance Systems. EURASIP Journal on Image and Video Processing:30 pages, 2008. URL http://dx.doi.org/10.1155/2008/824726.
[2] A. Sobral. BGSLibrary: An OpenCV C++ Background Subtraction Library. Workshop de Visao Computacional (WVC), 2013. URL http://dx.doi.org/10.13140/2.1.1740.7044.
[3] B. Laugraud, P. Latour, M. Van Droogenbroeck. Time Ordering Shuffling for Improving Background Subtraction. Advanced Concepts for Intelligent Vision Systems (ACIVS), 2015. URL http://hdl.handle.net/2268/184370.
[4] C. Stauffer, E. Grimson. Adaptive Background Mixture Models for Real-Time Tracking. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2:246-252, 1999. URL http://dx.doi.org/10.1109/CVPR.1999.784637.
[5] H. Wang, D. Suter. A Consensus-Based Method for Tracking: Modelling Background Scenario and Foreground Appearance. Pattern Recognition, 40(3):1091-1105, 2007. URL http://dx.doi.org/10.1016/j.patcog.2006.05.024.
[6] P.-M. Jodoin, S. Piérard, Y. Wang, M. Van Droogenbroeck. Overview and Benchmarking of Motion Detection Methods. In Background Modeling and Foreground Detection for Video Surveillance (T. Bouwmans and F. Porikli and B. Hoferlin and A. Vacavant, ed.). Chapman and Hall/CRC, 2014. URL http://www.crcnetbase.com/doi/abs/10.1201/b17223-30.
[7] L. Maddalena, A. Petrosino. A Self-Organizing Approach to Background Subtraction for Visual Surveillance Applications. IEEE Transactions on Image Processing, 17(7):1168-1177, 2008. URL http://dx.doi.org/10.1109/TIP.2008.924285.
[8] M. Van Droogenbroeck, O. Barnich. Visual Background Extractor. 2009. URL https://patentscope.wipo.int/search/en/detail.jsf?docId=WO2009007198.
[9] N. Goyette, P.-M. Jodoin, F. Porikli, J. Konrad, P. Ishwar. A Novel Video Dataset for Change Detection Benchmarking. IEEE Transactions on Image Processing, 23(11):4663-4679, 2014. URL http://dx.doi.org/10.1109/TIP.2014.2346013.
[10] O. Barnich, M. Van Droogenbroeck. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Transactions on Image Processing, 20(6):1709-1724, 2011. URL http://dx.doi.org/10.1109/TIP.2010.2101613.
[11] S. Brutzer, B. Höferlin, G. Heidemann. Evaluation of Background Subtraction Techniques for Video Surveillance. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR):1937-1944, 2011. URL http://dx.doi.org/10.1109/CVPR.2011.5995508.
[12] T. Bouwmans. Recent Advanced Statistical Background Modeling for Foreground Detection - A Systematic Survey. Recent Patents on Computer Science, 4(3):147-176, 2011. URL http://dx.doi.org/10.2174/2213275911104030147.
[13] T. Bouwmans. Traditional and Recent Approaches in Background Modeling for Foreground Detection: An Overview. Computer Science Review, 11-12:31-66, 2014. URL http://dx.doi.org/10.1016/j.cosrev.2014.04.001.
[14] Y. Goyat, T. Chateau, L. Malaterre, L. Trassoudaine. Vehicle Trajectories Evaluation by Static Video Sensors. IEEE Intelligent Transportation Systems Conference (ITSC):864-869, 2006. URL http://dx.doi.org/10.1109/ITSC.2006.1706852.
[15] Y. Wang, P.-M. Jodoin, F. Porikli, J. Konrad, Y. Benezeth, P. Ishwar. CDnet 2014: An Expanded Change Detection Benchmark Dataset. IEEE International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW):393-400, 2014. URL http://dx.doi.org/10.1109/CVPRW.2014.126.
[16] Z. Zivkovic. Improved Adaptive Gaussian Mixture Model for Background Subtraction. IEEE International Conference on Pattern Recognition (ICPR), 2:28-31, 2004. URL http://dx.doi.org/10.1109/ICPR.2004.1333992.