| (4.10) |
Considérons une source discrète sans mémoire, notée S. Supposons que cette source corresponde à un alphabet de n symboles différents, appelé alphabet de source :
| A1, A2, ..., An | (4.8) |
| p(A1), p(A2), ..., p(An) | (4.9) |
| (4.10) |
La connaissance de la probabilité d'émission de chaque symbole de la source permet de déduire l'information propre associée à chaque symbole :
| -log2p(A1), - log2p(A2), ..., - log2p(An) | (4.11) |
Cette grandeur représente l'information moyenne par symbole (ou incertitude moyenne par symbole). En base 2, l'entropie s'exprime en bit par symbole. Plus l'entropie de la source est grande, plus il y a d'incertitude et donc d'information liée à la source. Dans cette définition, il est supposé que tous les symboles ont une probabilité d'émission non nulle. On montre que l'entropie est maximale et vaut log2n lorsque tous ses symboles sont équiprobables. En effet, prenons le cas d'une source binaire comprenant les deux symboles A1 et A2, telle que
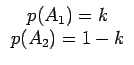
| H(S) = - k log2k - (1 - k)log2(1 - k) | (4.13) |
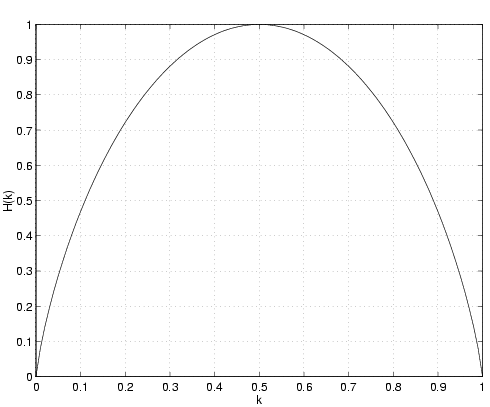
L'entropie est une fonction de la probabilité k. Notons, par soucis de clarté, la valeur de l'entropie de source comme une fonction de son argument H(k). Cette fonction est représentée à la figure 4.2.
On peut tout d'abord remarquer que l'entropie est nulle pour k = 1 (le symbole A1 est émis avec certitude) et pour k = 0 (le symbole A2 est émis avec certitude), ce qui correspond au cas où il n'y a aucune incertitude sur le symbole émis par la source. De plus, l'entropie atteint son maximum pour k = 0, 5 -la source a alors une entropie d'information de 1 [b/symbole]- , ce qui correspond au fait que les deux symboles sont équiprobables. En d'autres mots, il est tout aussi probable que la source émette le symbole A1 que le symbole A2.
Le raisonnement précédent est aisément généralisé au cas d'une source à n symboles équiprobables: p(A1) = p(A2) = ... = p(An) = 1/n , et l'entropie maximale de la source vaut alors
| Hmax(S) | = | - |
(4.14) |
| = | - |
(4.15) | |
| = | log2n | (4.16) |
Une source de 8 symboles équiprobables génèrent donc des symboles dont en moyenne 3 bits d'information par symboles. Ce résultat est intuitivement satisfaisant car, de fait, il faut au plus 3 bits pour représenter toutes les valeurs de la source.
L'entropie d'une source représente donc l'incertitude liée à cette source. Plus il est difficile de prédire le symbole émis par une source, plus grande est son entropie.